
琉球大学 上田 裕一 上田 英代 神戸学院大学 樺島 忠夫 統計数理研究所 村上 征勝
<計量分析の目的>
国文学の分野での計量分析はまだ日が浅く、源氏物語に関しては非常に数多くのデータが手作業で提出されているが、それを統計的に分析されているものは数少ない。
また源氏物語が54帖という長編であるために、紫式部一人ですべて書いたのかという疑問は古来よりあり、宇治十帖他作家説、竹河巻他作家説については、多くの研究がなされているが未だはっきりとした結論はでていない。また、一連の成立過程に関する疑問も解決されていない。こうした状況に対し、手作業では困難な各種の文法情報をコンピュータを使って処理し、統計的手法で分析することにより様々な課題への解答を試みたい。
<宇治十帖他作家説の概略>
古くは、15世紀一条兼良による「花鳥余情」に宇治十帖大弐三位作説があり、近代に入っては与謝野晶子が、和歌の巧拙から宇治十帖大弐三位作説をとっている。昭和32年には安本美典氏が、初めて統計的手法を用いて、前44帖と宇治十帖を比較検討し、宇治十帖が他作家による可能性が高いと結論づけている。
<成立過程論の概略>
大正11年和辻哲郎氏[1]は、作品自体の構図の弱さを指摘し、同一作家による作品への疑問や、執筆順序への疑問を提出した。次に昭和14年青柳秋生氏[2]は、最初から23帖までの登場人物を分析し、若紫グループと帚木グループの二つにわけ帚木グループは、若紫グループのあとに後期挿入されたとした。その後昭和25年武田宗俊氏[3]は、登場人物の検討範囲を33帖にまで広げグループを紫上系と玉鬘系に分け、やはり玉鬘系の巻々が紫上系巻々の後に挿入されたとした。巻毎の執筆順に関しては、論争が繰り返されたが、はっきりとした結論を見ていない。
更に昭和48年甲斐睦朗氏[4]は、「夕顔」巻の構成に疑問を投げかけ、この巻が同一時期に書かれたのではなく、徐々に加筆されて完成したのではないかとの画期的な説を提出した。平成元年上田[5]は、「夕顔」巻だけでなく、前半44帖すべての巻において巻毎の執筆順ではなく巻の中の節毎に検討するべきであるとして、「空蝉」「夕顔」の巻の検討、「源典侍」という人物の検討を行なった。
| 前後 □△△△□△□□□□□□△□□△△□□□□□△△ | |
| ○×××○×○○○○○○ ○○××○○○○○×××××× | |
|
桐帚空夕若末紅花葵賢花須 明澪蓬関絵松薄朝少玉初胡螢常篝 壷木蝉顔紫摘葉宴 木散磨 石標生屋合風雲顔女鬘音蝶 夏火 花賀 里 |
| ××××○○ | |
|
野行藤真梅藤若若柏横鈴夕御幻匂紅竹橋椎総早宿東浮蜻手夢 分幸袴木枝裏菜菜木笛虫霧法 宮梅河姫本角蕨木屋舟蛉習浮 柱 葉上下 橋 |
<古文の自動単語分割>
現代文にしろ、古文にしろ、各作品各作家の文体を計量的に分析するためには、まず、各文章をある単位に分割し、品詞分類する必要がある。その上で文の長さや、和歌の使用頻度、位置、各品詞の使用頻度などを計量化していく訳である。
文章の自動単語分割に関しては、現代文では筑波大の萩野網男氏、古文では大阪樟蔭大の西端幸雄氏が、多大な成果を挙げられている。我々は、同音異義語や細かい品詞分類については、最終的には、手作業による修正が必要であると考え、54帖という大部をできるだけ早く、単位認定に統一性を持たせつつ自動分割することを目的とした。
<自動単語分割への作業経過>
1)データ入力
テキストは、『源氏物語大成』(池田亀鑑編著)で、テキストに選んだ理由は、原文にできるだけ近く、校異が精密であり、語彙索引が完備していることによる。
まずOCR(富士電気XP−50S)で読み取り、手作業で修正した。読み取り作業そのものは、のべ23時間ほどで終わった。修正作業の主なものは、この機械が漢字第二水準に対応していない為その漢字を修正入力すること、踊り字を入れること、繰り返し記号に文字数分の記号を入れることなどである。(図1)
2)手作業による句点分割
次に、『日本古典文学大系』(岩波書店)を参考にして、句点を付けた。但し大系本で終止形でも、大成本で終止形でないものは、句点を付けなかった。句点を付けた理由はコンピュータ処理がしやすくなることと、自動単語分割の正確さを増す為である。
3)分割用辞書作り
イ)源氏物語1〜8巻までを手作業で単語分割する。その単語集を作る。その辞書を使って1〜8巻までを自動分割し、(図2)手作業による分割との同一性を確認する。その後、分割していない巻を自動分割する。(図3)
| <=いつれ-><=の-><=御時-><=に-><=か->。<=女御->更衣<=あまた-><=さふらひ-><=給-><=ける-><=なか-><=に-><=<=いと-><=やむことなき->-><=きは-><=には-><=あら-><=ぬ-><=か-><=すくれ-><=て-><=時めき-><=給-><=あり-><=けり->。<=はしめ-><=より-><=我-><=は-><=と-><=思あかり-><=給へ-><=る-><=御方¥¥めさましき-><=もの-><=に-><=おとしめ-><=そねみ-><=給->。<=おなし-><=ほと-><=それ-><=より-><=下らう-><=の-><=更衣-><=たちは-><=まして-><=やすから-><=す->。<=あさ-><=ゆふ-><=の-><=宮つかへ-><=に-><=つけて-><=も-><=人->の<=心-><=を-><=のみ-><=うこかし-><=うらみ-><=を-><=おふ-><=つもり-><=に-><=や-><=あり-><=けむ-><=いと-><=あつしく-><=なり-><=ゆき-><=もの心ほそけに-><=さと-><=かち-><=なる-><=を-><=い-><=よ->¥¥<=あ-><=かす-><=あはれなる-><=物-><=に-><=おもほし-><=て-><=人-><=の-><=そしり-><=を-><=も-><=え-><=はゝから-><=せ-><=給は-><=す-><=世-><=の-><=ためし-><=に-><=も-><=なり-><=ぬ-><=へき-><=御もてなし-><=也->。<=かんたちめ-><=うへ人-><=なと-><=も-><=あいなくめ-><=を-><=そはめ-><=つ->ゝ<=いとまはゆき-><=人-><=の-><=御おほえ-><=なり->。<=もろこし-><=に-><=も-><=かゝる-><=こと-><=の-><=おこり-><=に-><=こそ-><=世-><=も-><=みたれ-><=あしかり-><=けれ-><=と-><=やう->¥¥<=あめのした-><=に-><=も-><=あちきなう-><=人-><=の-><=もてなやみくさ-><=に-><=なり-><=て-><=楊貴妃-><=の-><=ためし-><=も-><=ひき-><=いて-><=つ-><=へく-><=なり-><=ゆく-><=に-><=いと-> |
|
<=世の中-><=かはり-><=て-><=後-><=よろつ-><=ものうく-><=おほされ-><=御身-><=の-><=やむことな-><=さも-><=そふ-><=に-><=や-><=かる¥¥しき-><=御->し<=の-><=ひ-><=ありき-><=も-><=つゝましう-><=て-><=こゝ-><=も-><=かしこ-><=も-><=おほつかなさ-><=の-><=なけき-><=を-><=かさね-><=給ふ-><=むくひ-><=に-><=や-><=なを-><=われ-><=に-><=つれなき-><=人->の<=御-><=心を-><=つきせす-><=のみ-><=おほし-><=なけく->。<=今-><=は-><=まして-><=ひまなう-><=たゝ人-><=の-><=やうに-><=て-><=そひ-><=おはします-><=を-><=いま-><=きさき-><=は-><=心やましう-><=おほす-><=に-><=や-><=うちに-><=のみ-><=さふらひ-><=給へ-><=はた-><=ち-><=ならふ-><=人-><=なう-><=心-><=や-><=すけ-><=なり->。 <=おりふし-><=に-><=したかひ-><=て-><=は-><=御あそひ-><=なと-><=を-><=このましう-><=世-><=の-><=ひ->ゝ<=く-><=はかり-><=せ-><=させ-><=給-><=つゝ-><=今->の<=御-><=ありさま-><=しも-><=めてたし->。 <=たゝ-><=春宮-><=を-><=そい-><=とこ-><=ひ-><=しう-><=思ひ-><=きこえ-><=給->。<=御-><=う-> <=しろみ-><=の-><=なき-><=を-><=うしろめたう-><=おもひ-><=きこえ-><=て->大將<=の-><=君-><=に-><=よろつ-><=きこえ-><=つけ-><=給ふ-><=も-><=かたはら-><=いたき-><=ものから-><=うれし-><=と-><=おほす->。 |
ロ)『フロッピー版古典対照語い表』(笠間書院)より源氏物語に使われている語のみの辞書を作る。『古典対照語い表』の源氏物語の語彙は、『源氏物語大成』の総索引から採られているもので好都合であった。
しかし、ここで作られた辞書には、濁音、半濁音があるのでそれをすべて清音になおした。この辞書で自動分割した結果が(図4)である。ここでは平仮名の見出し語のみを使ったので、漢字は分割されていない。
| <=いつれ-><=の->御時<=に-><=か->。女御更衣<=あまた-><=さふらひ->給<=け->る<=なか-><=に-><=いと-><=やむ-><=こと-><=な-><-き-><=きは-><=には-><=あ-><=ら-><=ぬ-><=か-><=すく->れ<=て->時<=め-><=き->給<=ありけ->り。<=はしめ-><=よ->り我<=は-><=と->思<=あかり->給<=へ->る御方¥¥<=めさまし-><=き-><=もの-><=に->お<=とし-><=め-><=そねみ->給。<=おなし-><=ほと-><=それ-><=よ->り下<=らう-><=の->更衣<=たち-><=は-><=まして-><=やす-><=からす->。<=あさゆふ-><=の->宮<=つか-><=へに-><=つけ-><=て-><=も->人<=の->心<=をの-><=みう-><=こか-><=し-><=うらみ-><=を-><=おふ-><=つもり-><=に-><=や-><=ありけ->む<=<=い-><=と->-><=あつし-><=く-><=なり-><=ゆき-><=もの->心<=ほ-><=そ-><=けに-><=さとかち-><=なる-><=を-><=<=い-><=よ->->¥¥<=あかす-><=あはれ-><=なる->物<=に-><=お<=も->-><=ほし-><=て->人<=の-><=そしり-><=を-><=も-><=え-><=は->ゞ<=から-><=せ->給<=はす->世<=の-><=ためし-><=に-><=も-><=なり-><=ぬ-><=へ-><=き->御<=もてなし->也。<=かんたちめ-><=<=う-><=へ->->人<=なと-><=も->あ<=い-><=なく-><=め-><=を-><=そはめ-><=つ->ゝ<=いとま-><=は-><=ゆき->人<=の->御<=おほえ-><=なり->。<=もろこし-><=に-><=も-><=か->ゝる<=ことの-><=おこり-><=に->り<=に-><=こそ->世<=も-><=みたれ-><=あ-><=しか->り<=け->れ<=と-><=やう->¥¥<=<=あ-><=め->-><=の-><=し-><=たに-><=も->あちきなう人<=の-><=もてなやみくさ-><=に-> |
ハ)手作業で分割した1〜8巻までの辞書と『古典対照語い表』の辞書とを合成し、『古典対照語い表』中のすべての動詞(終止形のみ収録)に活用形を追加した辞書を作った。語彙数は、37931語である。
4)自動単語分割
イ)単語の自動分割をより正確なものとするため、テキストに更に大系本を参考に、読点を付けた。
ロ)イ)のテキストを、すべてを合成した辞書で自動分割した結果が、(図5)である。150語ずつサーチして切ってゆくプログラムなので、桐壷の巻を分割するのに1時間27分かかった。
| <=いつれ->の<=御時->にか。<=女御->・<=更衣-><=あまた-><=さふらひ->給<=ける-><=なかに->、<=いと->、<=やむことなき->ゝは<=には-><=あら-><=ぬか->、<=すくれ->て<=時めき->給<=ありけ->り。<=はしめよ->り、我はと、<=思あかり-><=給へる-><=御方¥->、<=めさましき-><=もの->に<=おとしめ-><=そねみ->給。<=おなし-><=ほと->、<=それ-><=より-><=下らう->の<=更衣-><=たちは->、<=まして->、<=やすからす->。<=あさゆふ->の<=宮つかへ->に<=つけて->も、人の心<=をの->み<=うこかし->、<=うらみ->を<=おふ-><=つもり->にや<=ありけ->む、<=いと->、<=あつしく-><=なりゆき->、<=もの心ほそけに-><=さとかち-><=なる->を、<=いよ¥¥-><=あかす-><=あはれなる->物に<=おもほし->て、人の<=そしり->をも、え<=はゝから->せ<=給はす->、世の<=ためし->にも<=なり->ぬ<=へき-><=御もてなし->也。<=かんたちめ->・<=うへ人-><=なと->も、<=あいなく->、めを<=そはめ-><=つゝ->、<=いと->、<=まはゆき->、人の御<=おほえなり->。<=もろこし->にも、<=かゝる->、<=ことの-><=おこり-><=にこそ->、世も<=みたれ-><=あしかり-><=けれ->と、<=やう¥¥->、<=あめのした->にも、<=あちきなう->、人の<=もてなやみくさ->に<=なり->て、<=楊貴妃->の<=ためし->も、<=ひきいて->つ<=へく-><=なりゆく->に、<=いと->、<=はしたなき-><=こと-><=おほかれ->と、<=かたしけなき-><=御心はへ->の、<=たくひなき->を<=たのみ-><=にて->、<=ましらひ->給。<=ちゝ->の<=大納言->は<=なくなり-> |
<自動単語分割の今後の展開>
完全ではないがここまでの自動分割で、単語分割の作業のかなりの部分が、省力化できた。手作業による修正作業の後、各品詞に記号をつけた辞書で分割すると更に品詞分類のスピードアップが期待できるであろう。ここで得られた各種の文法情報によって源氏物語を計量的な視点から分析し、複数作家説、成立過程論の中の後期挿入説等々の様々な課題にも何らかの解答を見出していきたい。
この方法は、単に源氏物語にのみ有効なだけでなく、大半の古文に応用可能である。平安期の他の作品群の自動単語分割、品詞分類が手早く進めば、源氏物語との比較研究もより精緻なものへと発展しうるであろう。
<計量分析の試み>
日本語文献の計量分析として、すでに日蓮の文献を対象とした研究があり、文の長さ、語長、一文あたりの語数などの文に関する情報や品詞の使用率、品詞間の接続関係、(名詞+動詞の割合…)などの文法情報に基づき様々な統計手法を用いた分析が行われている。本研究は『源氏物語』という大部を対象とするため、日蓮文献の研究に比べても多くの情報が利用できると思われる。今回は一連の作業過程の中で、各巻における文の数、長さの情報は比較的早く得られたので、各巻ごとの総字数(図6)平均文長(図7)等を示す。
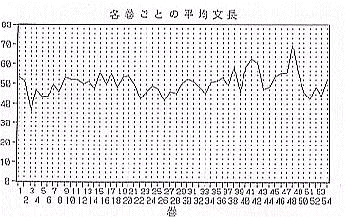
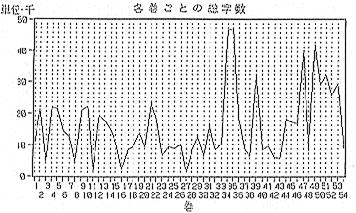
前半の44帖の平均文長は49.73(文字数)で宇治十帖の平均文長は52.05であった。数字上は若干の差があるが、統計的には差があるとはいえない。次に文長のデータを数量化Ⅲ類にかけて、紫上系と玉鬘系の類以性を調べてみた。その結果が(図8)である。
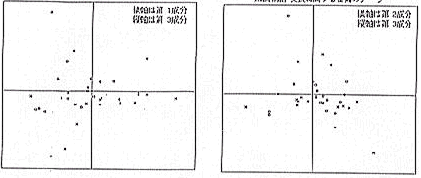 |
紫上系と玉鬘系では第1成分、第2成分には差異は出ていないが、第3成分の値は紫上系の各巻は一般に大きく、逆に玉鬘系では小さい傾向が見られる。
ただ残念な事に第1成分は平均文長(右に位置する巻ほど平均文長が短くなる傾向がある)、第2成分は変動係数(上に位置する巻ほど変動係数が小さくなる傾向がある)に関係する量と考えられるが、第3成分は今のところ解釈できていない。
文長のデータのみの分析ではこれ以上の詳細な分析はできないが、他の文法的な情報が得られば、更に細かい計量分析が可能になると考えられる。